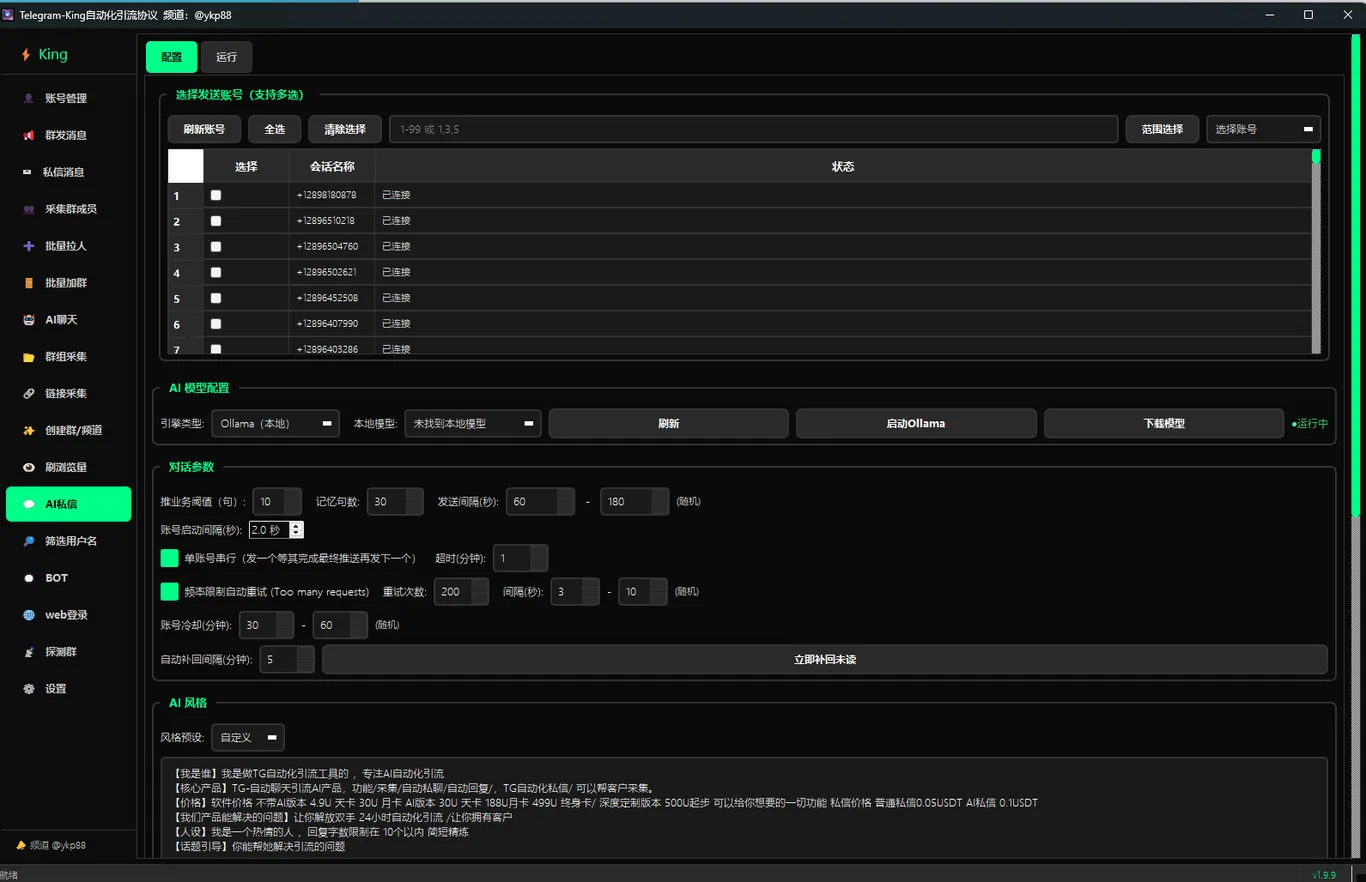
群发是把同一句话推给很多人,私信是把不同的话说给同一个人——这两件事看似都属于"主动触达",对话逻辑却完全相反。群发追求覆盖量,能容忍措辞固定;私信一旦让对方察觉到"这是模板",转化基本就断了。AI智能私信模块解决的,正是后半句:让每一段一对一对话尽量贴着真人节奏走,并在合适的时机把业务自然带出来,而不是开口就推。
对话由本地 AI 驱动,业务在节奏里带出
模块的对话生成依赖本地 Ollama 运行的 AI 模型,由它来逐句组织回复内容。和"踩到关键词就回固定话术"的脚本不同,AI 会结合上下文判断该说什么,因此同一个开场问题,面对不同的对方表述,回复也会有差别。
为了避免"上来就推销"这种最容易被反感的行为,模块用几个参数把推业务这件事约束在节奏里:
- 推业务阈值(句):对话累积到设定的句数后,AI 才会开始往业务方向引导,前面的句子用于建立基本对话氛围;
- 记忆句数:AI 会保留最近若干句的对话作为上下文,让回复能接得上前文,而不是每句都像重新开始;
- 发送间隔随机:每条消息之间的等待时间在区间内随机,模拟真人打字、思考的停顿,而非整齐划一地秒回。
这三项配合的结果,是把"何时说、记多少、隔多久"交给可调的规则,而不是一律照本宣科。具体阈值和句数应结合自己的话术长度去试,模块只提供可设置的位置,不替你决定数值。
单账号串行与风控自处理
私信场景下,账号安全比对话本身更脆弱。模块在执行层面做了几处约束来降低风险:
- 单账号串行:同一个账号同一时间只处理一段对话,不并发地同时和多人聊,避免行为过于密集;
- 超时控制:单次对话或单步等待超过设定时间会中止,不让流程无限挂着;
- 频率限制自动重试:触发平台的频率限制时,模块不会直接放弃,而是按规则自动重试;
- 账号冷却随机:账号在一轮工作后进入随机时长的冷却期再继续,错开固定节律;
- 自动补回未读:对方在冷却或间隔期间发来的新消息不会被漏掉,模块会自动把未读补回到对话流程里继续应答。
这些机制的共同目标,是让一个账号的对外行为在时间分布上更接近真人,而不是呈现出脚本特有的规律性。需要说明的是,这些只是降低账号风险的工程手段,并不构成任何"绝对安全"的承诺,平台规则本身仍是不可控因素。
AI 风格与人设可自定义
AI 说什么、以什么身份说,由你预先设定。模块开放了几个维度让对话有统一的"人设",而不是每个账号都讲一套话:
- 我是谁:给 AI 一个明确的身份定位;
- 核心产品:要推介的业务主体;
- 能解决的问题:业务对应的真实价值点,供 AI 在对话中引用;
- 话术引导:希望 AI 朝哪个方向带、用什么语气。
设定得越具体,AI 的回复越贴合你的实际业务;设定含糊,AI 就只能给出泛泛的对话。这部分基本决定了私信内容的质量,值得在正式跑量前多打磨几轮。
整体来看,这个模块更适合愿意先把人设和话术调清楚、再让 AI 接管对话节奏的使用方式;如果只想批量推同一句广告,群发类模块会更直接。
Q: 推业务阈值设多大合适?
A:模块只提供可设置的入口,不预设标准答案。阈值偏小会让 AI 过早提及业务、显得急;偏大则铺垫太长、效率低。建议结合自己话术的铺垫长度,从一个相对保守的句数起步再调整。
Q: 对方在冷却期间发来的消息会丢吗?
A:不会。模块有自动补回未读的机制,账号处于冷却或发送间隔期间收到的新消息,会在恢复后被纳入对话流程继续应答,而不是被直接跳过。